本文翻译自 Exposing NSMutableArray,译文原地址为NSMutableArray 原理揭露。
以下为译文:
我总好奇 NSMutableArray 内部是如何工作的。别误会,不可变数组确实提供了极大的便利。它们不仅线程安全,在对它们进行拷贝时也是完全自由的。但这些改变不了它们死板的事实——它们的内容不可被修改。我发现实际内存操作的细节很迷人,这也是我这篇文章聚焦于可变数组的原因。
当我在说明我是如何研究 NSMutableArray 的整个过程时,这篇文章会得相当具有技术性。会有一整个章节讨论 ARM64 汇编 (the ARM64 assembly),所以当你感觉到无聊时,不要犹豫,直接跳过那部分内容。一旦我们讨论完那些底层细节,我会展示关于这个类的隐藏特性。
NSmutableArray 的实现细节之所以私有是有原因的。得益于其底下的子类 (underlying subclasses) 和 ivar 布局 (ivar layouts),还有算法和数据结构的支撑,它们几乎可以随时改变。无视掉那些注意事项,我们值得去掀开 NSMutableArray 的引擎盖窥视一番,搞清楚它是如何工作的和能期望它做什么。接下来的学习基于 iOS 7.0 SDK。
和往常一样,你可以在我的GitHub上找到接下来的 Xcode 项目。
普通 C 数组的问题
任何典型的程序员都知道 C 数组的原理。可以归结为一段能被方便读写的连续内存空间。数组和指针并不相同 (详见 Expert C Programming 或 这篇文章),不能说:一块被 malloc 过的内存空间等同于一个数组 (一种被滥用了的说法)。
使用一段线性内存空间的一个最明显的缺点是,在下标 0 处插入一个元素时,需要移动其它所有的元素,即 memmove 的原理:
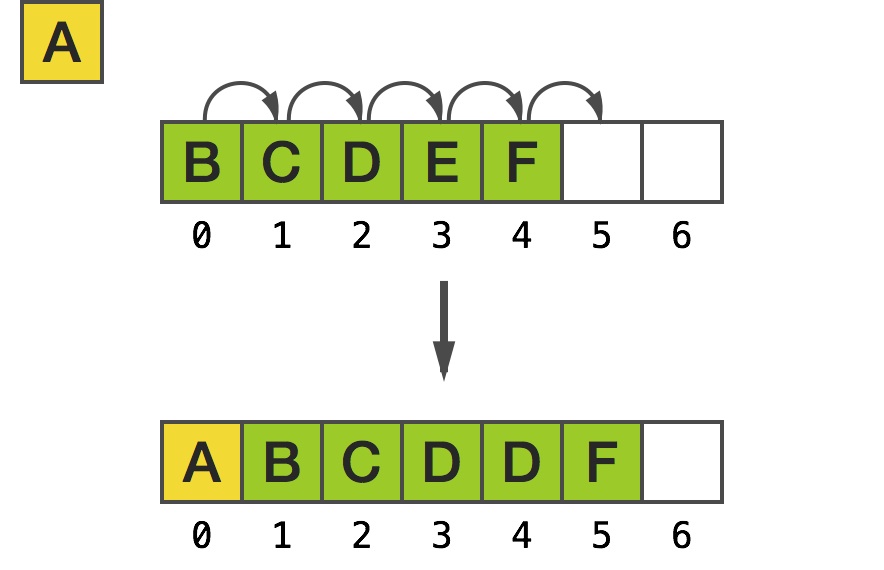
同样地,假如想要保持相同的内存指针作为首个元素的地址,移除第一个元素需要进行相同的动作:
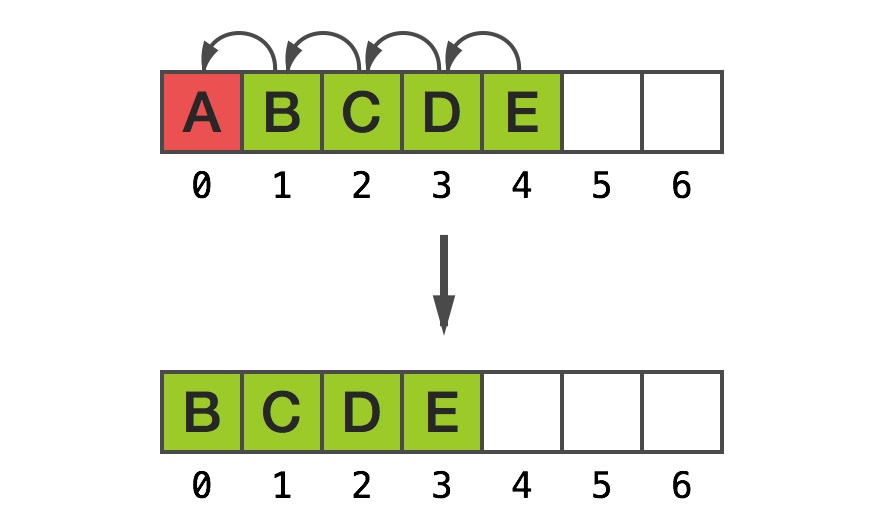
当数组非常大时,这样很快会成为问题。显而易见,直接指针存取在数组的世界里必定不是最高级的抽象。C 风格的数组通常很有用,但 Obj-C 程序员每天的主要工作使得它们需要 NSMutableArray 这样一个可变的、可索引的容器。
NSMutableArray
Diving in
尽管苹果公布了很多库的源码,Foundation 及其 NSMutableArray 却并没有被开源。不过,很多工具使得发掘其奥秘能稍微轻松一点。我们从尽可能高的层级开始,往底层去获取其它不可获取的细节。
获取并 dump 类
NSMutableArray 是一个类簇——其具体实现实际上是 NSMutableArray 本身的子类。+[NSMutableArray new] 实际上返回的是哪个类的实例呢?利用 LLDB 我们连代码都不用写就能知道:
有了类名,我们可以使用class-dump。这个方便的工具伪造了从提供分析的二进制获得的类的头文件。使用下面的一行命令,我们可以提取出我们感兴趣的 ivar 布局 (ivar layout):
我用了一个正则表达式,所以上面的命令不能获得全部的信息,但却提供了我们想要的结果:
原始输出的位字段被指定为 unsigned int 类型,但显然无法将 62 字节放入一个 32 字节的整型中—— class-dump 还未能对 ARM64 的库进行正确的解析。尽管有些小缺陷,但通过查看它的 ivars,已经能够了解很多关于该类的信息了。
反汇编类
在我的研究中,最重要的工具是 Hopper。我爱死这个反汇编程序了。它是那些想知道任何事物工作原理、充满求知欲的灵魂必不可少的工具。Hopper 最强大的特性是能生成类 C 语言伪代码,而且足够清晰地去掌握实现的要旨。
用来理解 __NSArrayM 最重要的方法是 - ObjectAtIndex:。Hopper 很好地给出了 ARMv7 的伪代码,但这些还不能在 ARM64 上好好工作。我想有 ARMv7 提供对应的提示来动手写这伪代码,会是一次很好的练习。
剖析方法
带着 ARMv8 Instruction Set Overview 和一堆有根据的推测,我想我正确地破译了该汇编代码。然而作为一个智慧的终极来源,你不应该相信接下来的分析。我还是个新手。
参数传递
作为起点,我们应该注意,每个 Obj-C 方法实际上是一个多了两个参数的 C 函数。第一个参数是 self,一个指向成为方法调用接收者的对象的指针。第二个参数是 _cmd,用于表示当前的 selector。
可以说,与 - objectAtIndex: 等价的 C 风格函数声明如下:
从 ARM64 开始,这些类型的参数就被传递给连续的寄存器,我们可以假设 self 指针在 x0 寄存器,_cmd 在 x1寄存器,还有对象的 index 在 x2 寄存器。对于参数传递的细节请参考 ARM Procedure Call Standard,需要注意 Apple 的 iOS 版本会有一些分歧。
分析汇编代码
这看起来有点恐怖。一次性分析一大块汇编代码可不是明智的行为,下面的代码我们会一步步来,理解每一行做了什么。
设置
我们从一段似乎是 ARM64 的函数序言 (function prologue)开始。先把栈中的 x29 和 x30 寄存器保存起来,然后将当前栈指针移动到 x29 寄存器:
在栈上开辟一些空间(减,因为栈向下增长):
我们感兴趣的路径代码似乎没有使用这段空间。然而,越界 (out of bounds) 异常抛出代码会调用一些其它函数,因此序言必须为此选项提供便利。
获取计数
接下来两行代码执行程序计数器相对寻址 (program counter relative addressing)。地址编码的具体细节相当复杂且文献稀少。Hopper 自动计算出了合理的偏移量:
上面的两行代码会获取位于 0x1d102c 内存空间的内容,然后存储在 x8 寄存器。那上面是什么呢?Hopper 可以帮到我们:
这是 __NSArrayM 类里的 _used ivar 的偏移量。为什么要那么麻烦去做额外的拉取,而不是简单地将变量 8 放到汇编程序中?原因就是易碎的基类 (fragile base class) 问题。现代 Objectie-C 通过让它自身在运行时可以选择去重写在 0x1d102c 的值(和所有该问题的其它 ivar 偏移量)来处理这个问题。如果 NSObject、NSArray 或 NSMutableArray 增加新的 ivar,旧的二进制文件仍然可以工作。
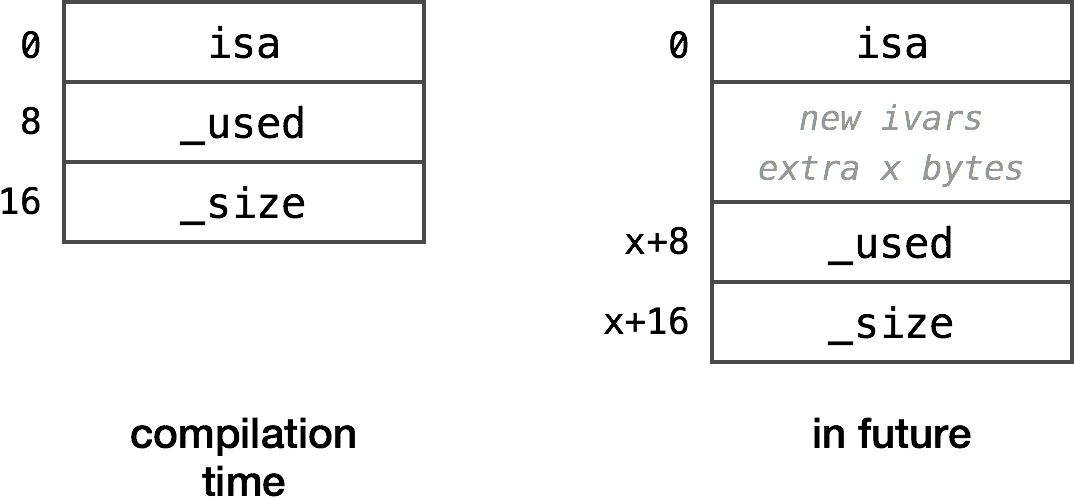
尽管 CPU 不得不做额外的内存拉取工作,但这却是个完美的解决方案,在 Hamster Emporium 和 Cocoa with Love 有更详细的解释。
现在我们知道了 _used 在类里面的偏移量。因为 Obj-C 对象和结构体没什么两样,我们也有了在 x0 处的这个结构体的指针,我们所需要做的便是拉取该值:
上面代码的 C 等价代码如下:
我更喜欢汇编版本。快速分析反汇编了的 __NSArrayM 的 - count 方法,揭示了 _used ivar 装载着 __NSArrayM 的元素数量,而此时我们拿到了它在 x8 寄存器的值。
边界检查
请求了在 x2 的索引值和 x8 的计数之后,下面的代码对两者做了比较:
当 x8 的值小于或等于 x2 的值时,会跳到 0xc33c 处用于处理异常抛出的代码。这是基本的边界检查。如果测试失败(计数小于或等于索引),会抛出异常。我不打算讨论这部分反汇编,因为它们真的没有介绍任何的新东西。如果通过了测试(计数大于索引),会继续简单地按顺序执行指令。
计算内存偏移量
我们前面看过这个,这次要拉取位于 0x1d1030 的 _size ivar 的偏移量:
然后检索它的内容并向右移动两位:
为什么要移动呢?我们看看 dump 出来的头文件:
原来是三个位字段分享了同个存储空间,所以要获得 _size 的实际值,我们要将值右移,丢弃留给 _doHardRetain 和 _doWeakAccess 的位。_doHardRetain 和 _doWeakAccess 的 ivar 偏移量恰好相同,但是它们的位存取代码显然不同。
接下来是同样的操作,我们拿到(位于 0x1d1034)_offset ivar 的内容,将其放入 x9 寄存器:
接下来的三行代码是最重要的代码。首先,比较了 _size(位于 x8)和 _offset + index(位于 x9):
然后基于上述比较的结果,有条件地选择一个寄存器的值。
相当于 C 语言的 ?: 运算符:
xzr 寄存器是一个含有值 0 的零寄存器,hi 是 csel 指令应该检查的条件码 (condition code) 的名字。在这个用例中,我们检查了比较的结果是否是更大(x8 的值是否大于 x9 的)。
最后,用 _offset + index(位于 x9)减去 x8 的新值,将结果再次存入 x8。
所以刚刚发生了什么?先看看等价的 C 语言代码:
在 C 代码中,我们无须右移 _size 和 _offset,编译器会为位字段的存取自动完成这些任务。
获取数据
我们快到达目的地了。先将拉取到的 _list ivar (0x1d1038) 的内容放到 x9 寄存器中:
这时,x9 指向含有数据的内存分段的开始。
最后,将存放在 x8 里的拉取到的索引值左移3位,与 x9 相加,并将内存里的内容放到 x0 的位置。
这里有两点很重要。第一,每个数据偏移量都以字节为单位。对一个值左移3位相当于将其乘于8,这个结果就是64位架构下指针的大小(8 个字节)。第二,结果存在 x0 的位置,即是存储一个返回 NSUInteger 的函数的返回值的寄存器。
这样我们就快完成了。我们拿到了正确的值并存入数组。
函数后记 (Function Epilog)
剩下的是一些样板操作,恢复调用之前的寄存器状态和栈指针:
全部放到一起
我解释了这些代码是干啥的,但问题是为什么要这么做?
ivars 的意思
我们来概括下每个 ivar 的意思:
- _used 是计数的意思
- _list 是缓冲区指针
- _size 是缓冲区的大小
- _offset 是在缓冲区里的数组的第一个元素索引
C 代码
带着 ivars 和分析了的汇编代码,我们现在可以写一个执行了相同操作的 Objective-C 代码:
汇编代码肯定要长的多。
内存布局
最关键的部分是决定 realOffset 应该等于 fetchOffset(减去 0)还是 fetchOffset 减 _size。看着纯代码不一定能画出完美的图画,我们设想一下两个关于如何获取对象的例子。
_size > fetchOffset
这个例子中,偏移量相对较小:
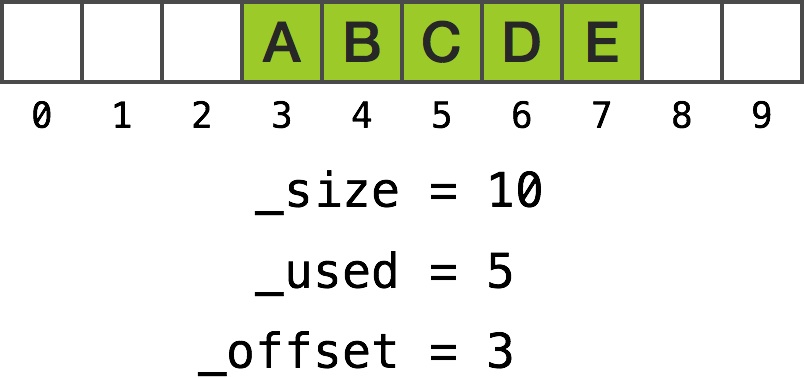
为了获取 0 处的对象,我们计算出 fetchOffset 等于 3 + 0。因为 _size 大于 fetchOffset,realOffset 也等于 3。代码返回 _list[3] 的值。而获取 4 处的对象时,fetchOffset 等于 3 + 4,代码返回 _list[7]。
_size <= fetchOffset
当偏移量比较大时会怎样?
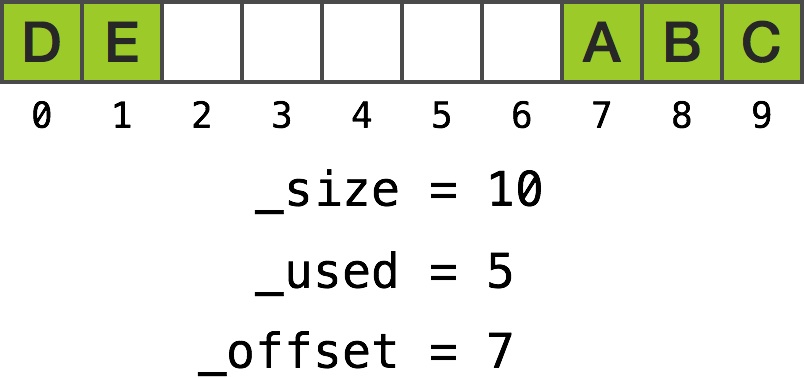
获取 0 处的对象,使得 fetchOffset 等于 7 + 0,调用方法后如期望的返回 _list[7]。然而,获取 4 处的对象时,fetchOffset 等于 7 + 4 = 11,要大于 _size。获得的 realOffset 要从 fetchOffset 减去 _size,即 11 - 10 = 1,方法返回 list[1]。
我们基本上是在做取模运算,当穿过缓存区边界时会转回缓冲区的另一端。
数据结构
正如你会猜测的,__NSArrayM 用了环形缓冲区 (circular buffer)。这个数据结构相当简单,只是比常规数组或缓冲区复杂点。环形缓冲区的内容能在到达任意一端时绕向另一端。
环形缓冲区有一些非常酷的属性。尤其是,除非缓冲区满了,否则在任意一端插入或删除均不会要求移动任何内存。我们来分析这个类如何充分利用环形缓冲区来使得自身比 C 数组强大得多。
__NSArrayM 特性
对剩下的反汇编了的方法进行逆向工程将会给出 __NSArrayM 内部的明确解释,我们可以利用发现的数据点在更高的等级研究该类。
在运行时检查
为了在运行时检查 __NSArrayM,我们不能简单地粘贴 dump 了的头文件。首先,测试程序在没有为 __NSArrayM 提供一个至少为空的 @implementation 块时不会被链接。加上这个 @implementation 块并不是个好主意。当程序编译和已经运行时,我不完全确定运行时会决定使用哪一个类(如果你知道,请告诉我)。为了安全的缘故,我重命名了类名使得某些东西能独立出来—— BCExploredMutableArray。
再则,ARC 不会让我们在没有指定它的所属关系前编译 id *_list。我们不会将其写入 ivar,所以预先指定 id 为 __unsafe_unretained 会对内存管理提供最少的干预。无论如何,我选择了声明 ivar 为 void _list**,原因稍后便知晓。
打印出代码
我们可以创建一个 NSMutableArray 的类别 (category),它会打印出 ivars 和包含在数组里面的所有指针列表的内容:
结果
在两端插入或删除会相当地快
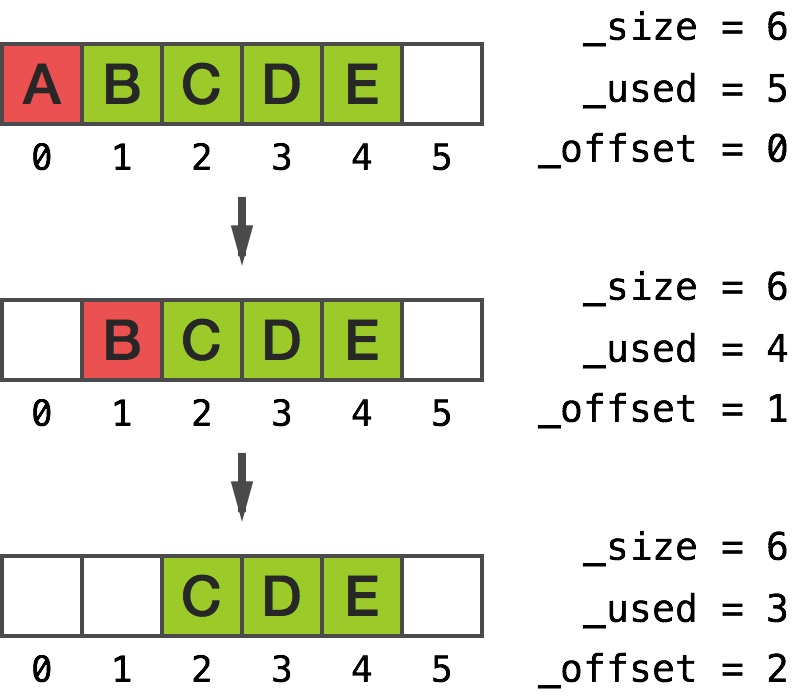
我么来思考一下一个非常简单的例子:
输出显示移除位于 0 处的对象两次后,只是简单地清除了指针并由此而移动了 _offset ivar:
这是对上面所做的事的图形化说明:
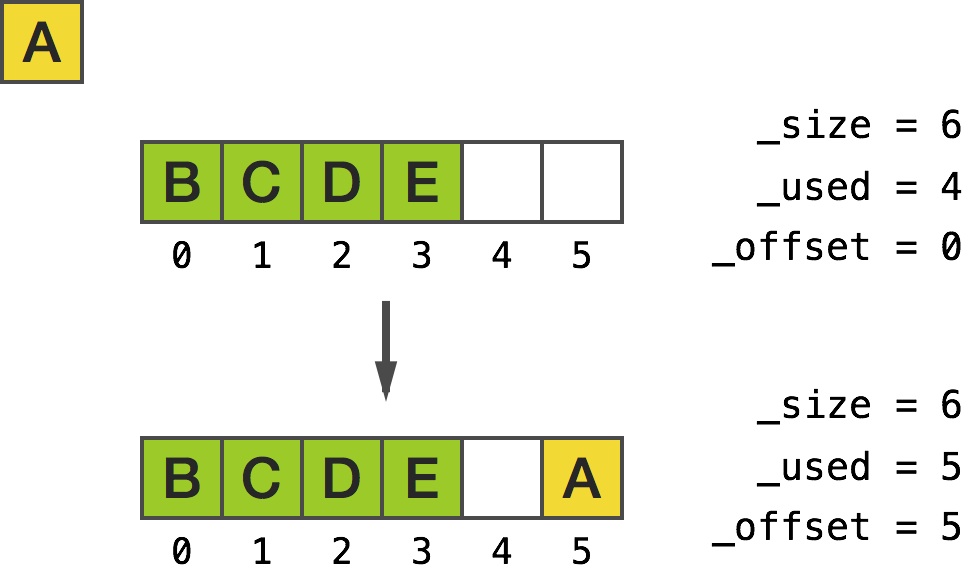
添加元素会怎样呢?我们在一个全新的数组下试试:
在 0 处插入对象用了环形缓冲区魔法来将新插入的对象放置在缓存区的末端:
如下图描述:
这是个很棒的消息!这意味着 __NSArrayM 可以对任意一端进行处理。你可以使用 __NSArrayM 作为栈或队列而没有任何性能问题。
从另一侧说明,你可以看到,在 64 位架构之下的 NSNumber 如何使用参数指针 (tagged pointers) 来作为存储。
非整数的增长因子
好吧,这里我稍微作了点弊。虽然我也已经做了一些实验性测试,但我想有一个确切的值,并且我已经偷窥了 insertObject:atIndex: 的反汇编程序。每当缓冲区满了,它会重新分配1.625倍大小的空间。我很惊讶它居然不等于 2。
更新:Mike Curtiss 给出了一个关于为什么调整因子等于 2 只是次优选择的非常好的解释。
一旦增长,不再缩小
这有点令人震惊:__NSArrayM 从不减少它的大小。我们运行下面的代码试试:
尽管这里的数组是空的,它仍然保持着很大的缓冲区:
除非你使用 NSMutableArray 去加载一些超大量的数据并且清除数组是为了释放空间,否则这不是你要担忧的问题。
初始化容量几乎完全不重要
我们用设置为2的连续乘方的初始化容量来分配新数组空间:
真是意想不到:
在删除的时候不会清除指针
这虽然不怎么重要,但我发现它仍然有趣:
输出为:
当往前移动它的对象时,__NSArrayM 不会麻烦地去清除前一个空间。无论如何,对象没有被清除。这不是 NSNumber 在施展它的魔法,NSObject 也表现一致。
这解释了我为什么选择定义 _list ivar 为 void **。如果 _list 声明为 id *,那么接下来的循环将会在给 object 赋值时崩溃:
ARC 隐式地插入一个 retain/release 对,且控制着释放对象。尽管预先定义 id object 为 __unsafe_unretained 解决了问题,但我完全不想任何人或东西去调用这串游离指针的任何方法。这就是我使用 void ** 的原因。
最糟糕的情形是在中间进行插入或删除
这两个例子中,我们将会粗暴地从一个数组中间移除元素:
从输出中我们看到顶部的元素往下移动,底部为低索引(注意 [5] 处的游离指针):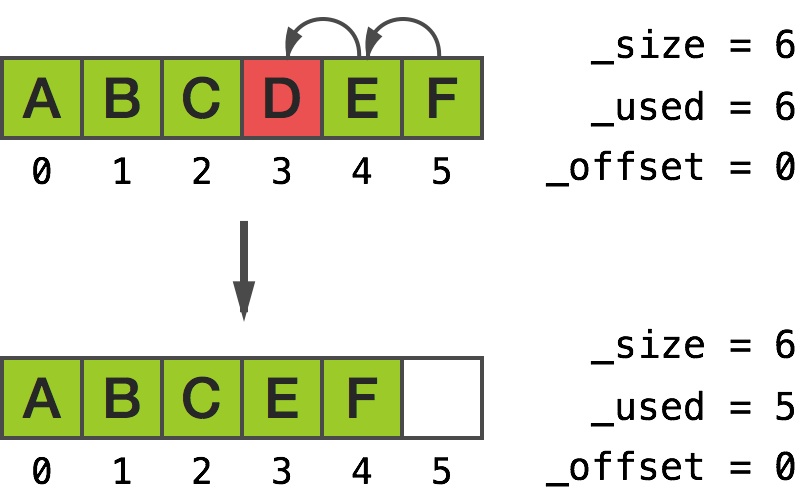
然而,当我们调用 [array removeObjectAtIndex:2] 时,底部的元素往上移动,顶部为高索引: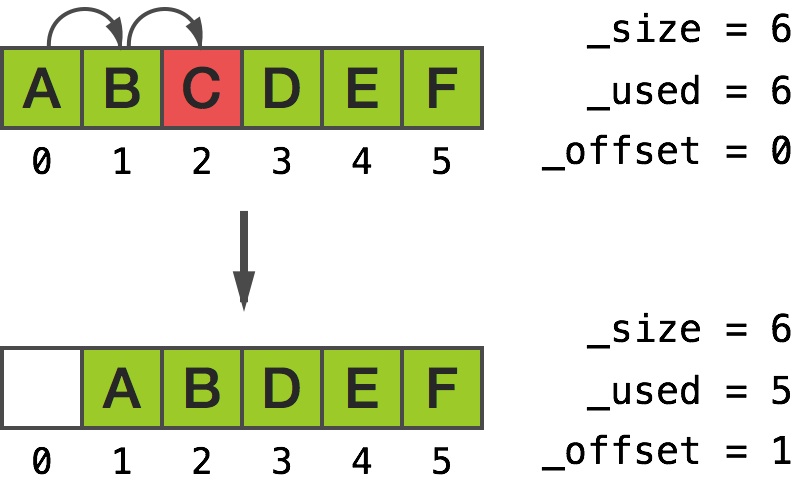
往中部插入对象有非常相似的结果。合理的解释就是,__NSArrayM 试着去最小化内存的移动,因此会移动最少的一边元素。
成为一个好的子类公民
正如 NSMutableArray Class Reference 的讨论,每个 NSMutableArray 子类必须实现下面 7 个方法:
- - count
- - objectAtIndex:
- - insertObject:atIndex:
- - removeObjectAtIndex:
- - addObject:
- - removeLastObject
- - replaceObjectAtIndex:withObject:
毫不意外的是,__NSArrayM 履行了这个规定。然而,__NSArrayM 的所有实现方法列表相当短且不包含 21 个额外的在 NSMutableArray 头文件列出来的方法。谁负责执行这些方法呢?
这证明它们只是 NSMutableArray 类自身的一部分。这会相当的方便:任何 NSMutableArray 的子类只须实现 7 个最基本的方法。所有其它高等级的抽象建立在它们的基础之上。例如 - removeAllObjects 方法简单地往回迭代,一个个地调用 - removeObjectAtIndex:。下面是伪代码:
然而,它是有道理的:__NSArrayM 重新实现了它超类的一些方法。例如,尽管NSArray 提供了 NSFastEnumeration 协议的 - countByEnumeratingWithState:objects:count: 方法默认实现,但 __NSArrayM 仍然有它自己的代码路径 (code-path)。
Foundations
我总觉得 Foundation 是 CoreFoundation 的小型封装器 (thin wrapper)。我的论点很简单:当 CF 类可用时,不需要重新发明实现了全新的 NS 类的轮子。当我知道 NSArray 或 NSMutableArray 和 CFArray 完全没有共同点时相当震惊。
CFArray
关于 CFArray 最好的特点便是:它是开源的。这将会是一个快速的概述,尽管源代码完全公开,饥渴地等着被阅读。CFArray 中最重要的函数是 _CFArrayReplaceValues。它被下面这些函数调用:
- CFArrayAppendValue
- CFArraySetValueAtIndex
- CFArrayInsertValueAtIndex
- CFArrayRemoveValueAtIndex
- CFArrayReplaceValues(注意前面没有下划线)
基本上,CFArray 移动内存空间是围绕这最高效趋势的变化,类似于 __NSArrayM 做得工作。然而,CFArray 不使用环形缓冲区。反而使用一个两端都填充着零的更大的缓冲区,使得枚举和获取正确的对象变得更加简单。在任意一端添加元素只是简单地吃到剩余的被填充的内存。
最后的话
尽管 CFArray 服务于稍微更通用些的目的,但我发现它吸引人的是,它的内部做着不是和 __NSArrayM 一样的事。尽管我以为发现一个共同的地方并且制造一个单一的、典型的实现会有用,但也许有一些其它的因素导致这样的分立。
这两者有什么共同点?它们是像双向队列这类抽象数据类型的具体实现。不管它的名字,NSMutableArray 是一个类固醇数组,剥除了 C 风格数组对应的缺点。
就我个人而言,我很高兴在任意一端插入或删除能有固定时间的性能。我不再对我自己使用 NSMutableArray 作为队列而质疑。它做得相当好。